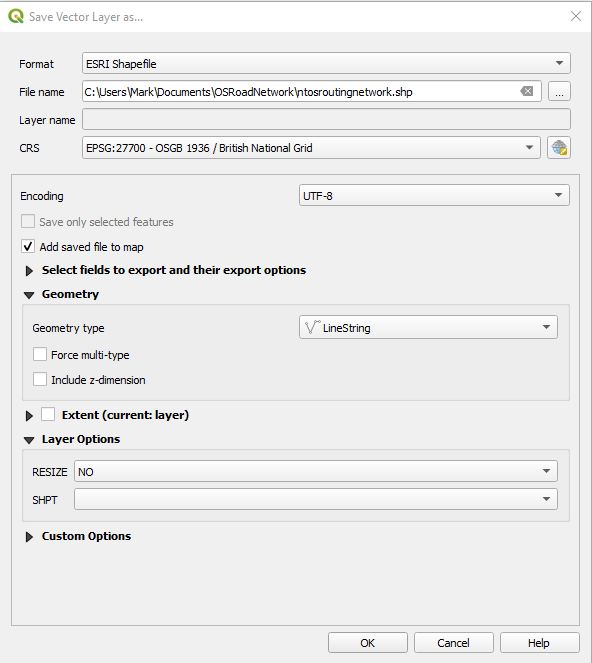
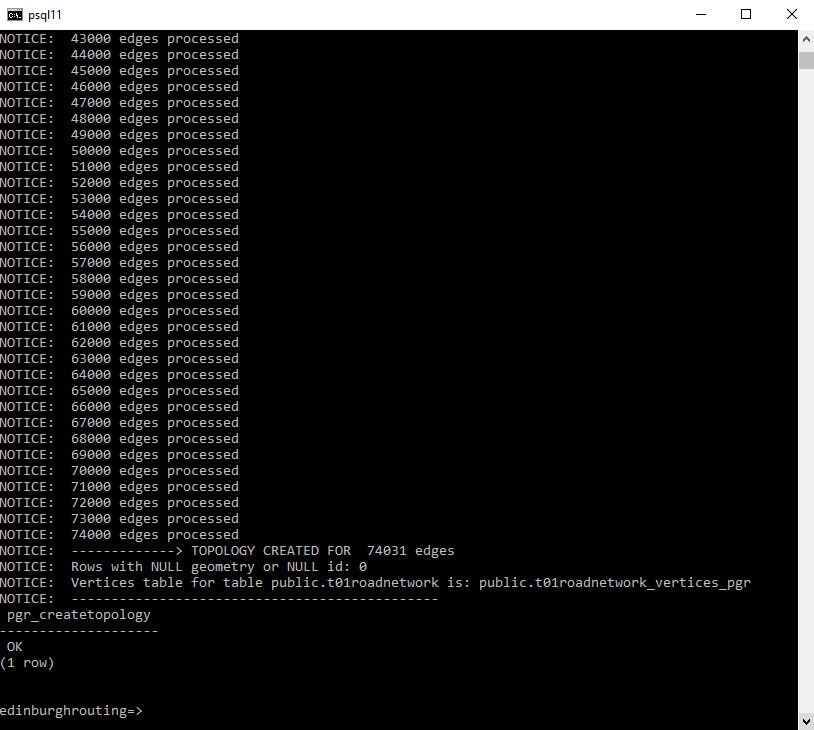
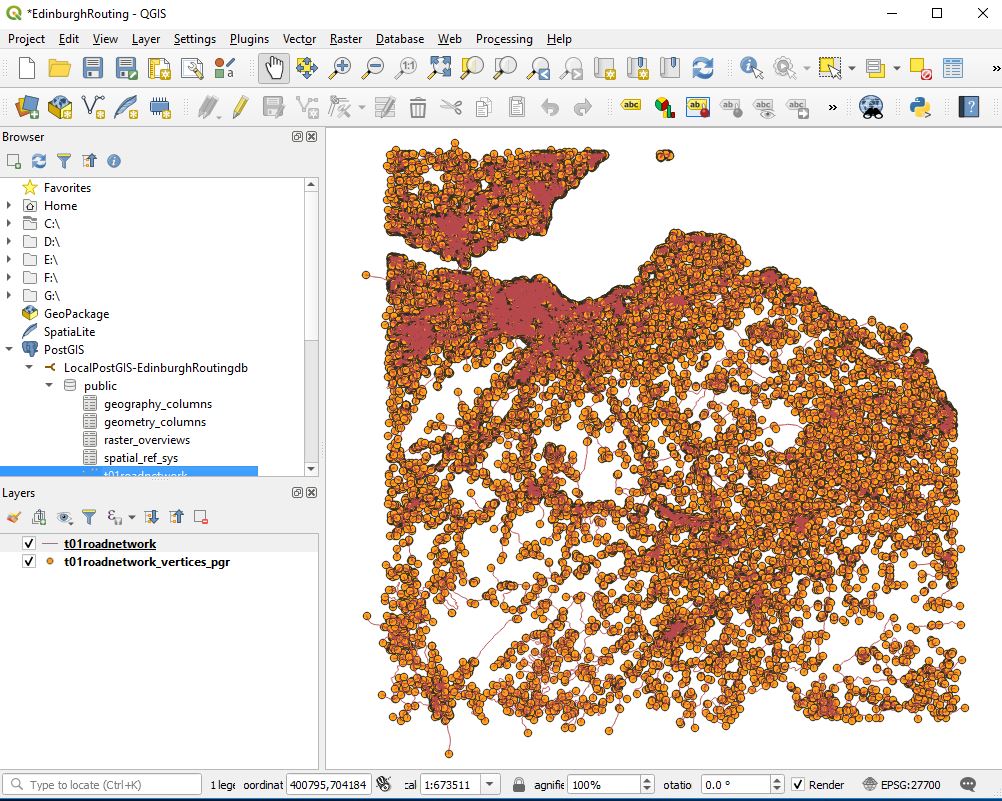
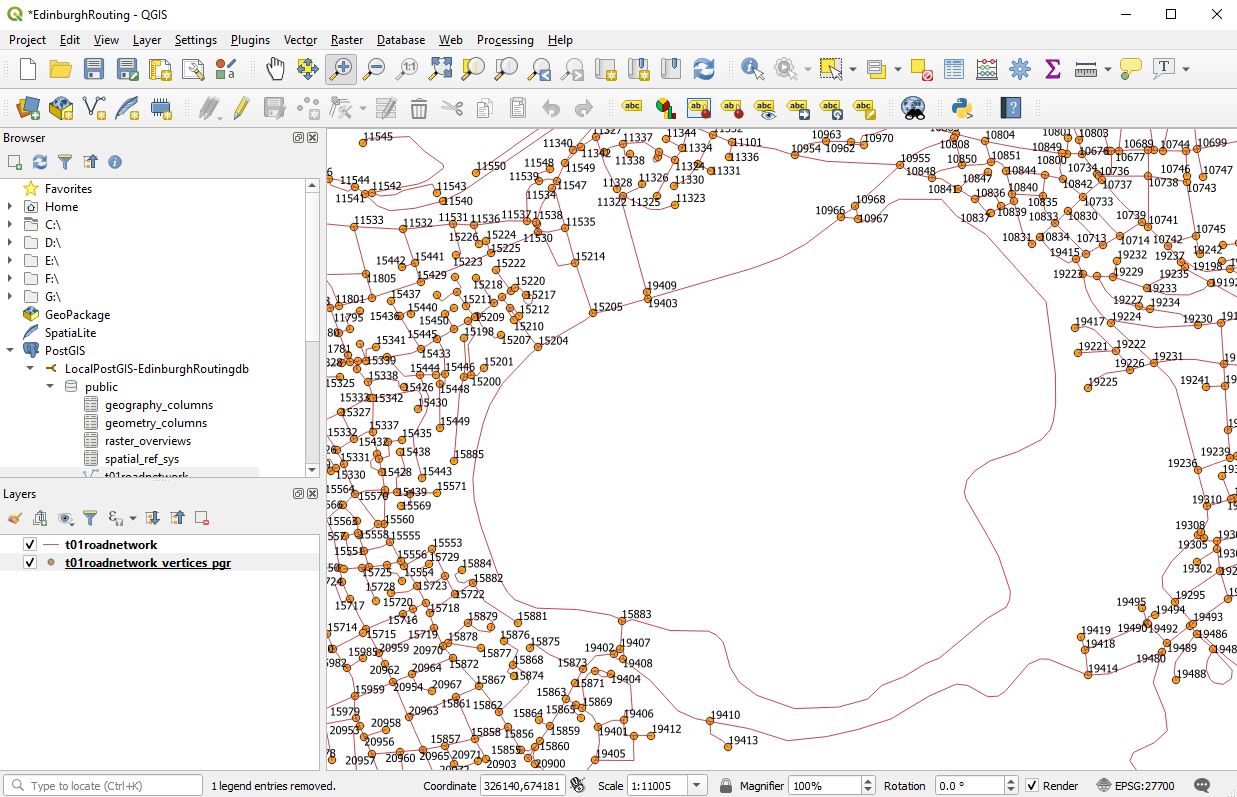
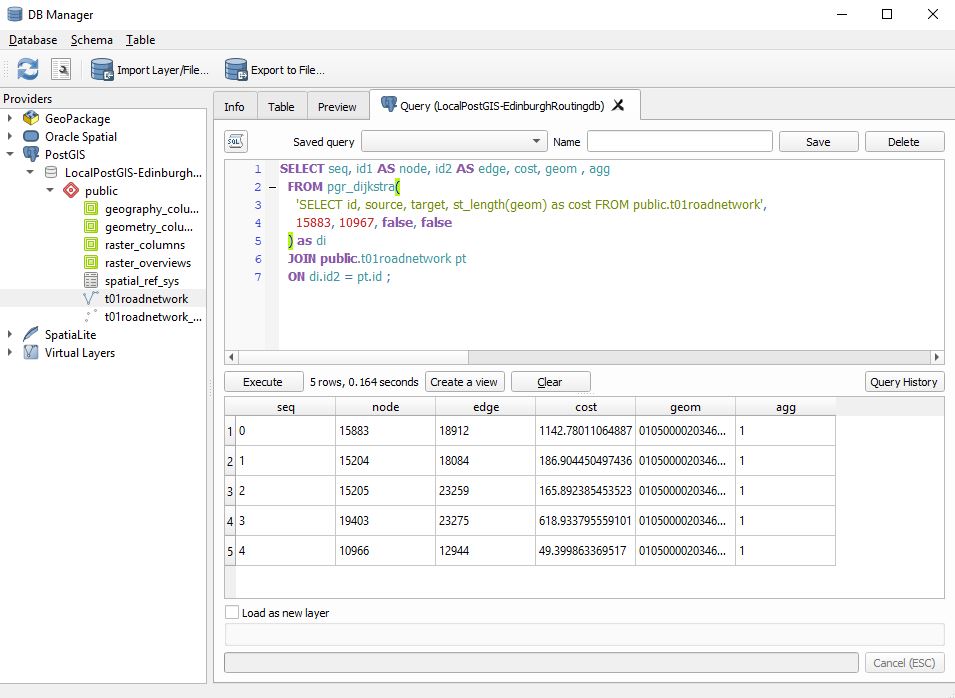
This is a post focused around Network distance measurement using POSTGIS and routing plugins.. This discusses the use of Ordnance survey Road Network information and its preparation in using it for routing.
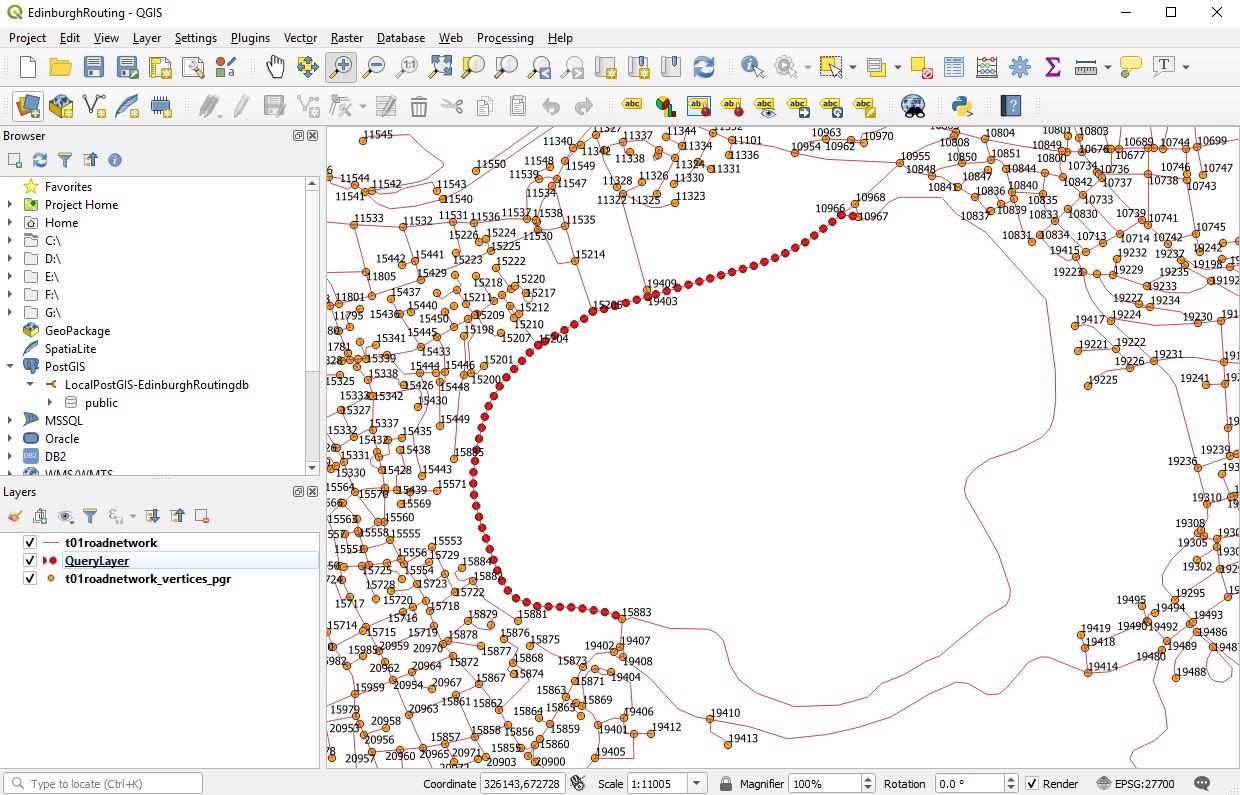
The Ordnance Survey open source road network layer includes roundabouts that have an attribute value of roundabout. Great but looking at them closely some of the constituent arcs are digitised in a clockwise direction while others are digitised in an anti-clockwise direction. When using dijkstra routing with weighting to prevent incorrect pathing it is necessary to ensure that networks are weighted in the correct fashion. Directional weighting only works if you know the direction and you weight appropriately. For use with directional routing in the UK roundabouts any directional weighting should prevent travel in anticlockwise direction. ST_reverse will correct incorrect direction BUT the Ordnance survey layer seems to have no attribute that consistently indicates whether an arc on a roundabout has or has not been digitised correctly. Marking lines with direction and viewing them we see the random nature of many arcs on roundabouts.
Here is Sheriff Hall Roundabout on Edinburgh City Bypass

Here is Straiton roundabout just north of the bypass
and finally Hermiston Gate roundabout again following the theme on Edinburgh city bypass
It got me thinking was there a way to determine whether arcs on roundabouts could be determined to be clockwise or anti-clockwise?
Having thought about it in my head quite a bit I determined that it probably would be possible if we knew three points and could create some kind of virtual graph with the start point being at 6 and a finish at 12 with mid points at 9 if travelling in a clockwise position and 3 if travelling in an anti-clockwise position.
I had a look around and the following post seemed to tally with the idea of three points and positive and negative relating to clockwise or anticlockwise.

Maths to determine direction of an arc
Having looked at this I set about working through the problem in Excel to see if I could get consistent results.
Firstly I created a set of directions North West South and East and placed some coordinates that could be used in calculations.

I then went forward and tested whether I could identify the direction of various arcs from these coordinates in excel using the formula identified on Stack Exchange.
Here I replaced a,b,c with b Beginning, m Middle and f Finish

And I decided to work through manually in excel to ensure that I had the maths correct.
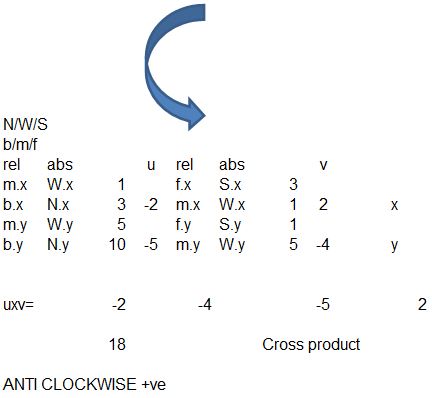
and further testing figures

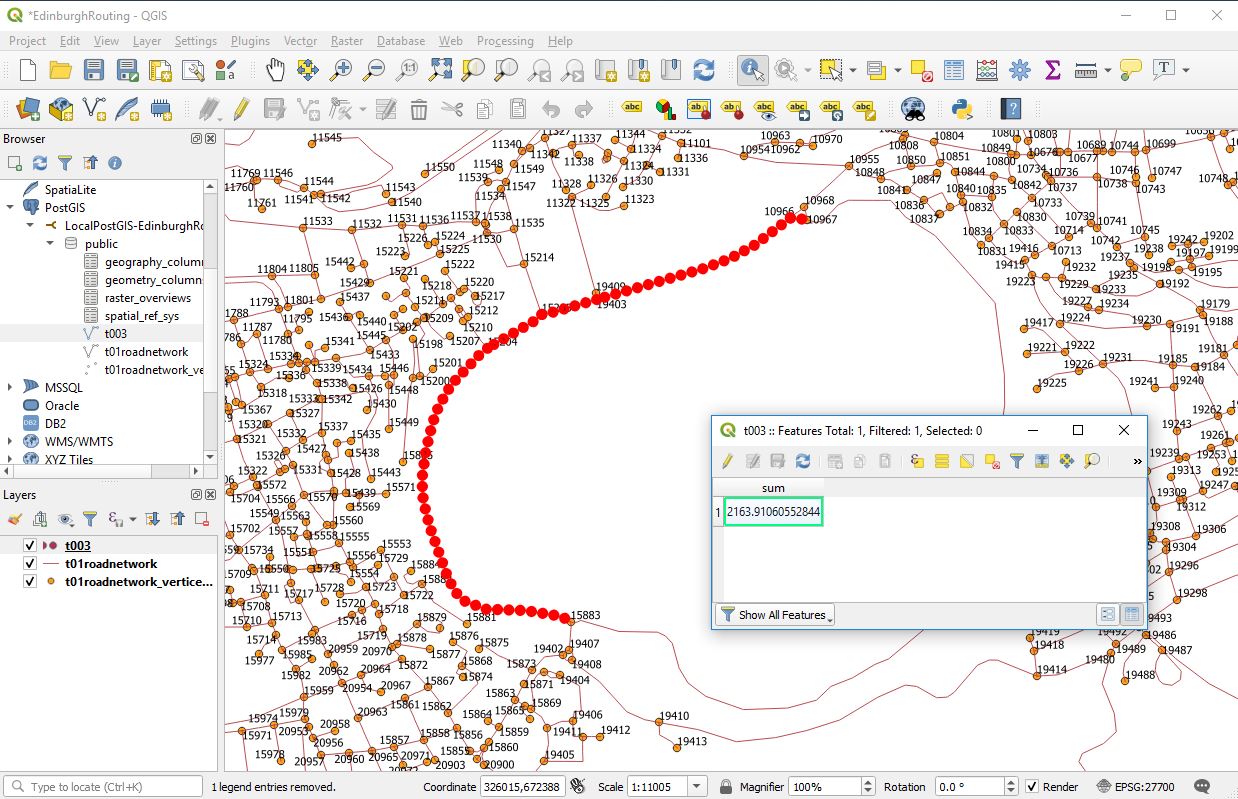
So firstly I create a separate table that just shows the roundabouts
CREATE TABLE t001roundaboutsntroadlink as select id pkidt001, st_linemerge(geom) as geom from ntroadlink where formofway = 'Roundabout';
In the above I use st_linemerge to ensure that all geometry is linestring as this is necessary to use the st_startpoint and st_endpoint postgis functions.
Next I added the the required variables from stack overflow algebra to the line table
ALTER TABLE t001roundaboutsntroadlink add column bx float(8), Add column by float(8), Add column mx float(8), Add column my float(8), Add column fx float(8), Add column fy float(8), Add column ux float(8), Add column uy float(8), Add column vx float(8), Add column vy float(8), Add column uxtimesvy float(8), Add column uytimesvx float(8), Add column uxv float(8);
Next I needed to identify a b beginning, m middle and f finish point for each line that I wanted to test.
b points (beginning)
CREATE TABLE t002bpoints AS SELECT pkidt001 as pkidt001,st_startpoint(geom) as geom, st_x(st_startpoint(geom)) as bx, st_y(st_startpoint(geom)) as by from t001roundaboutsntroadlink;
m points (middle)
CREATE TABLE t002mpoints AS SELECT pkidt001 as pkidt001,st_lineinterpolatepoint(geom,0.5) as geom, st_x(st_lineinterpolatepoint(geom,0.5)) as mx, st_y(st_lineinterpolatepoint(geom,0.5)) as my from t001roundaboutsntroadlink;
f points (finish)
CREATE TABLE t002fpoints AS SELECT pkidt001 as pkidt001,st_endpoint(geom) as geom, st_x(st_endpoint(geom)) as fx, st_y(st_endpoint(geom)) as fy from t001roundaboutsntroadlink;
It was then a case of simple update queries to complete the table
update t001roundaboutsntroadlink set bx = st_x(st_startpoint(geom)); update t001roundaboutsntroadlink set by = st_y(st_startpoint(geom)); update t001roundaboutsntroadlink set mx = st_x(st_lineinterpolatepoint(geom,0.5)); update t001roundaboutsntroadlink set my = st_y(st_lineinterpolatepoint(geom,0.5)); update t001roundaboutsntroadlink set fx = st_x(st_endpoint(geom)); update t001roundaboutsntroadlink set fy = st_y(st_endpoint(geom)); update t001roundaboutsntroadlink set ux=mx-bx; update t001roundaboutsntroadlink set uy=my-by; update t001roundaboutsntroadlink set vx=fx-mx; update t001roundaboutsntroadlink set vy=fy-my; update t001roundaboutsntroadlink set uxtimesvy = ux*vy; update t001roundaboutsntroadlink set uytimesvx= uy*vx; update t001roundaboutsntroadlink set uxv = uxtimesvy-uytimesvx;
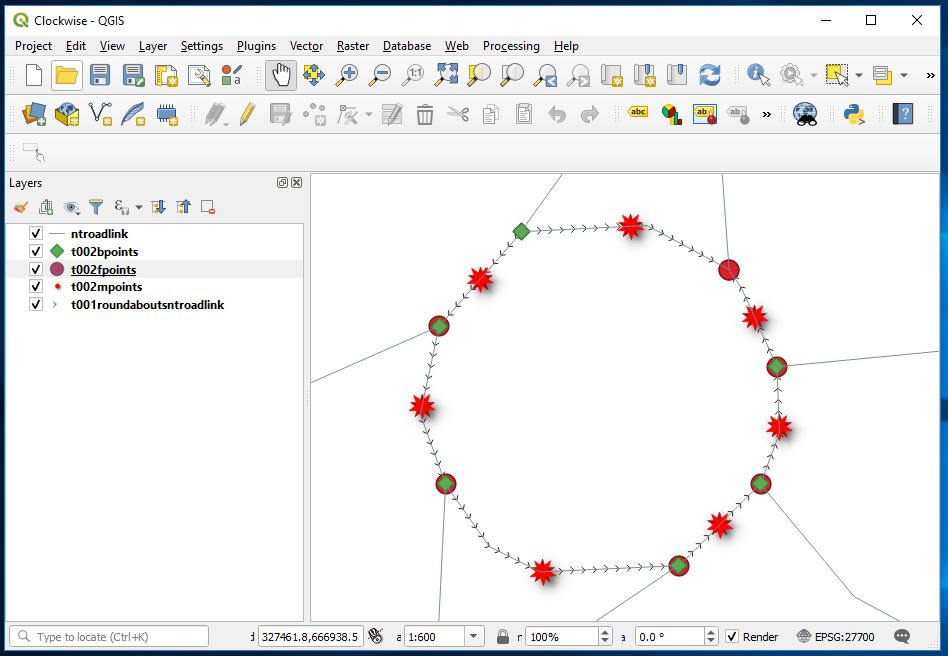
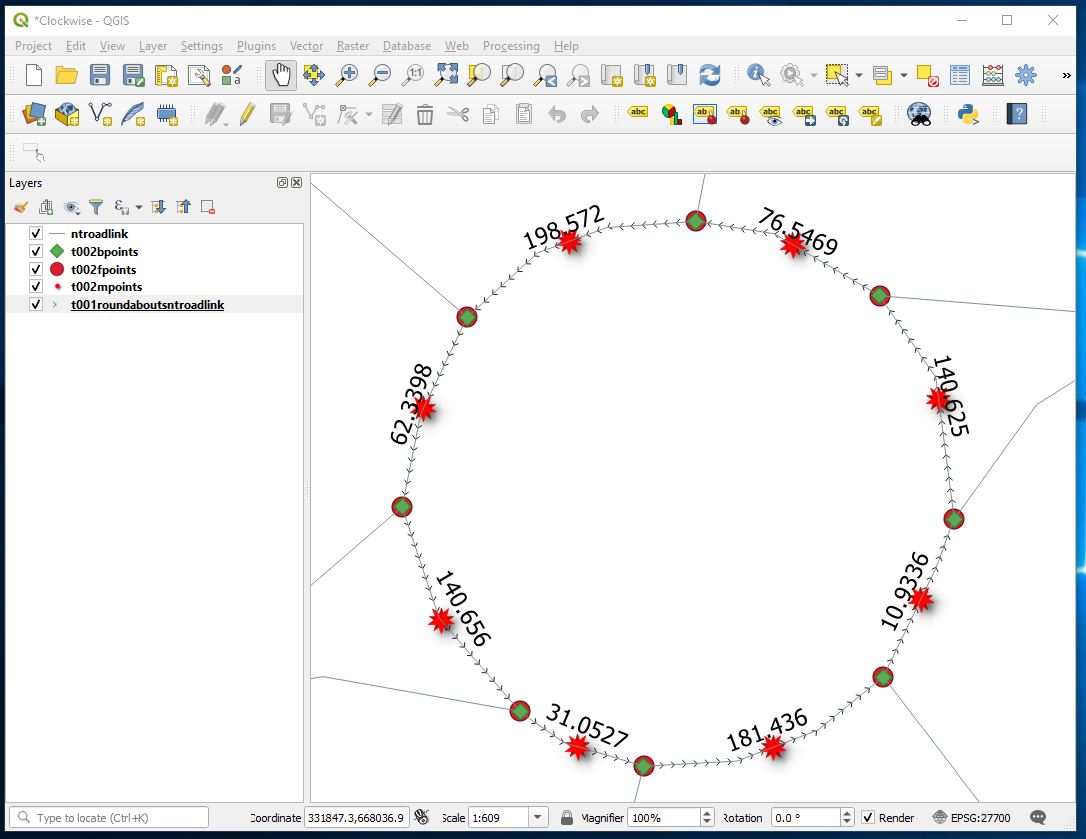
Labelling up the roundabouts Hermiston Gate now looks like
And Sheriff Hall Roundabout now looks like this
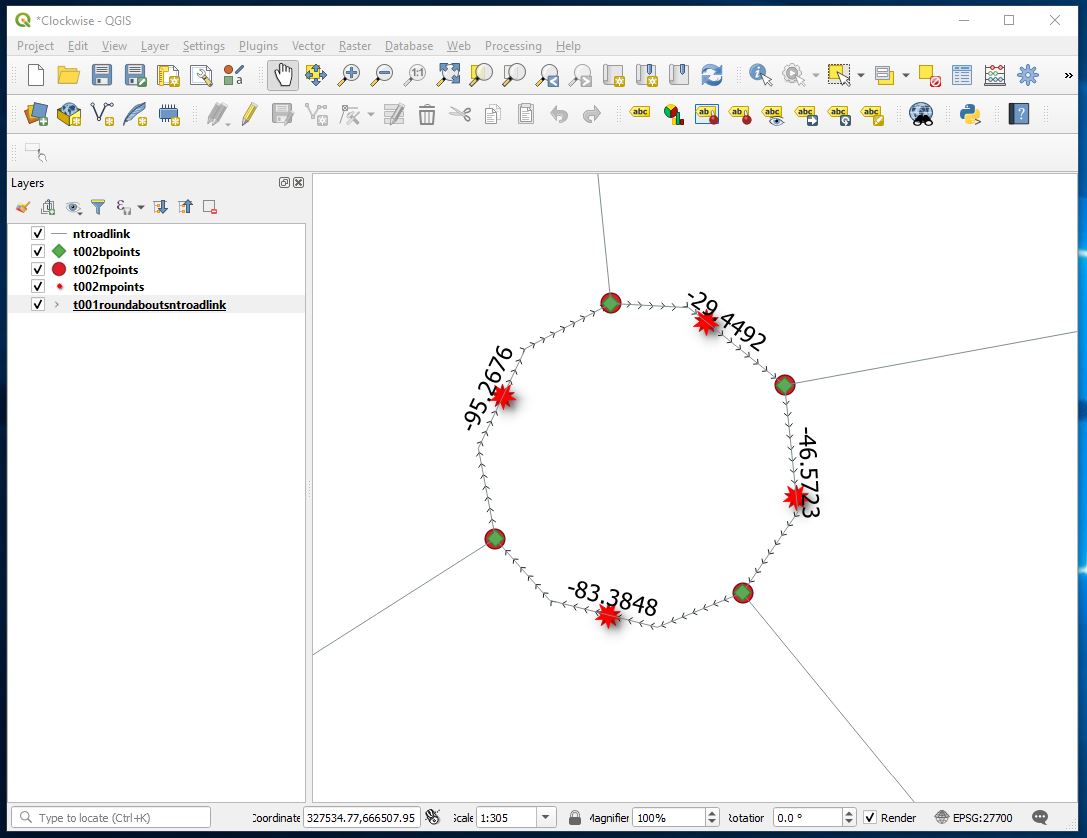
Compared with a correctly directed roundabout
CREATE TABLE t001roundaboutsntroadlinkcorrected AS TABLE t001roundaboutsntroadlink;
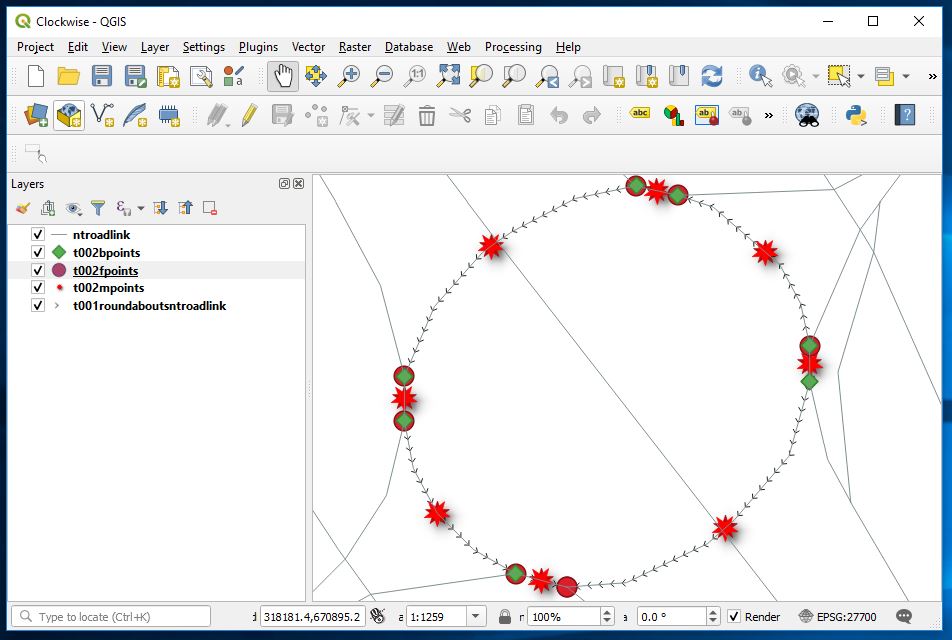
And now correct the items display as previous and see what we see.
UPDATE t001roundaboutsntroadlinkcorrected set geom = st_reverse(geom) where uxv > 0;
Sheriff hall roundabout now
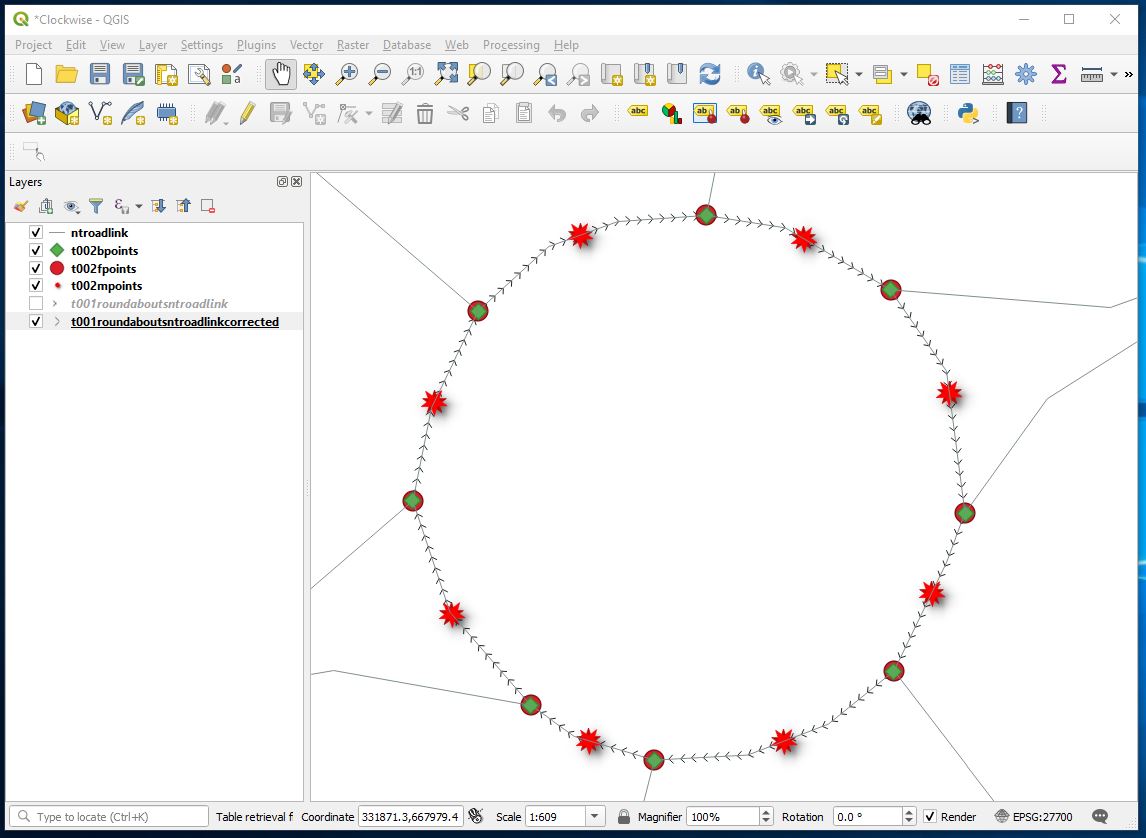
and some proof that reasonable number of lines were updated.
Which is an indication that all roundabouts arcs have been corrected properly
But a zero uxv value indicates a straight line.
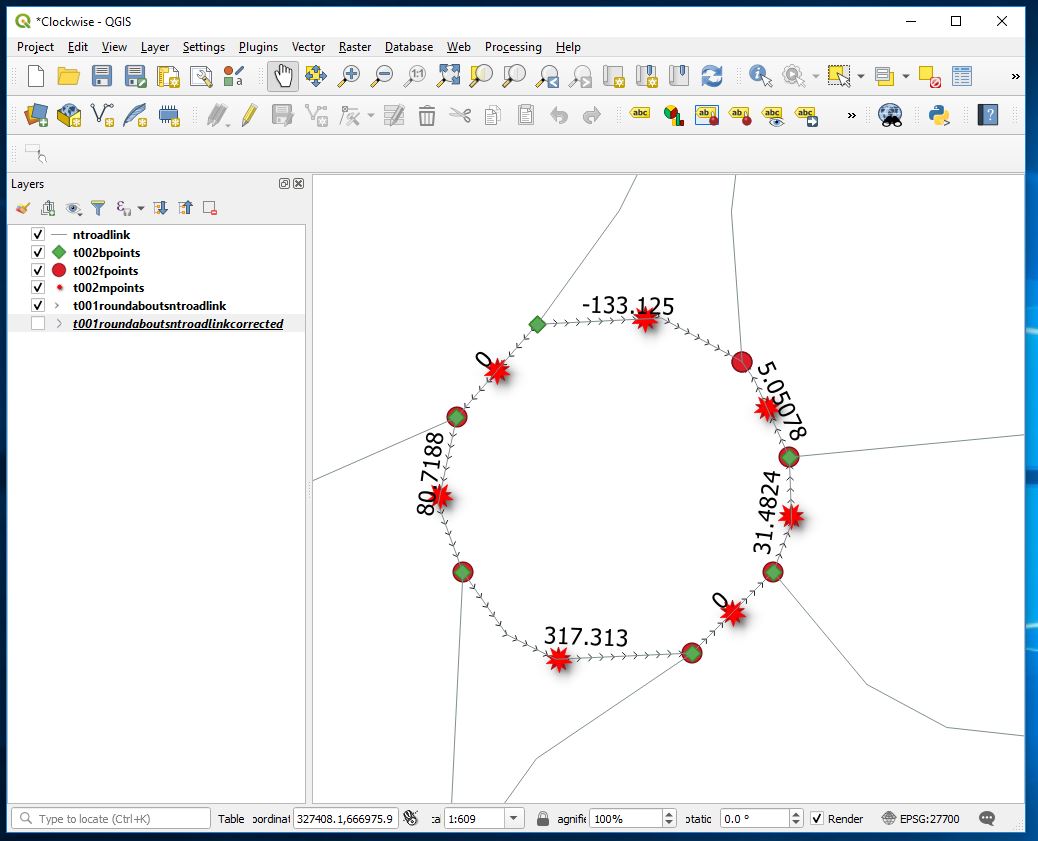
It should however be possible to match starts with finishes for overlying points and where a line has 0 value of uxv and its ends and finishes are not matched with adjacent opposites create a switch to reverse the direction of all lines that are incorrect compared to their neighbours thus only correcting incorrect directions. Haven’t done that in this case.