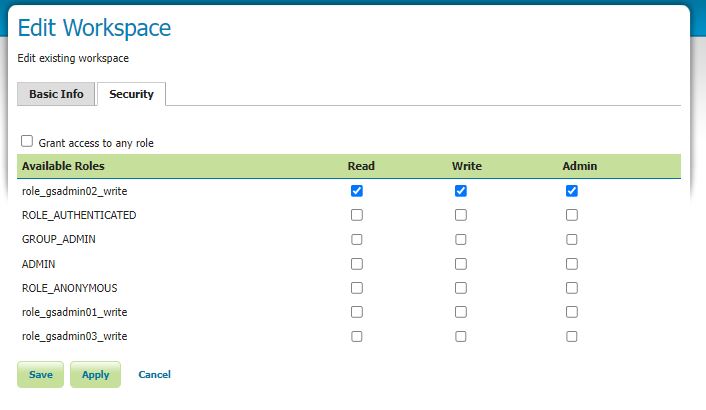
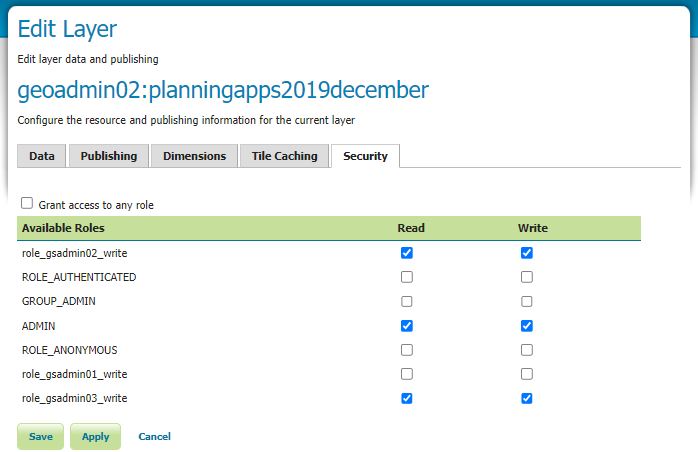
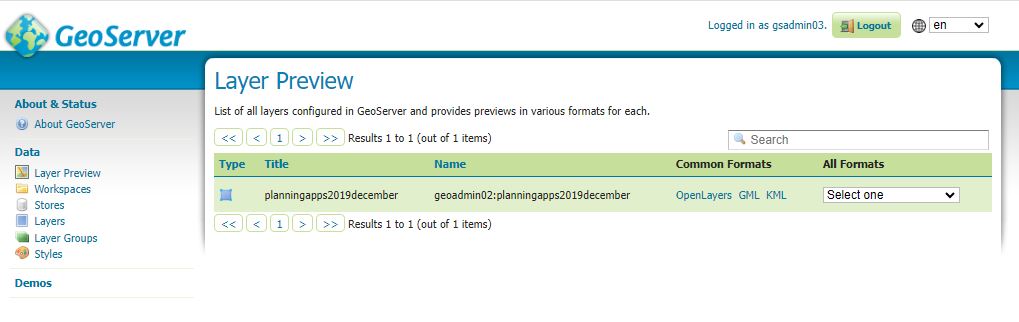
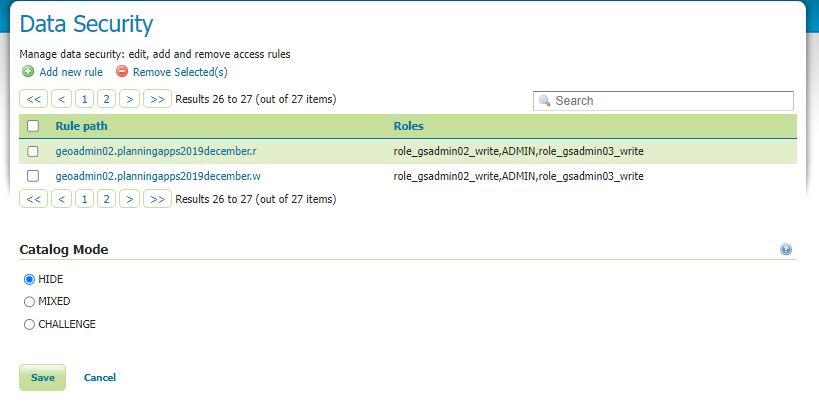
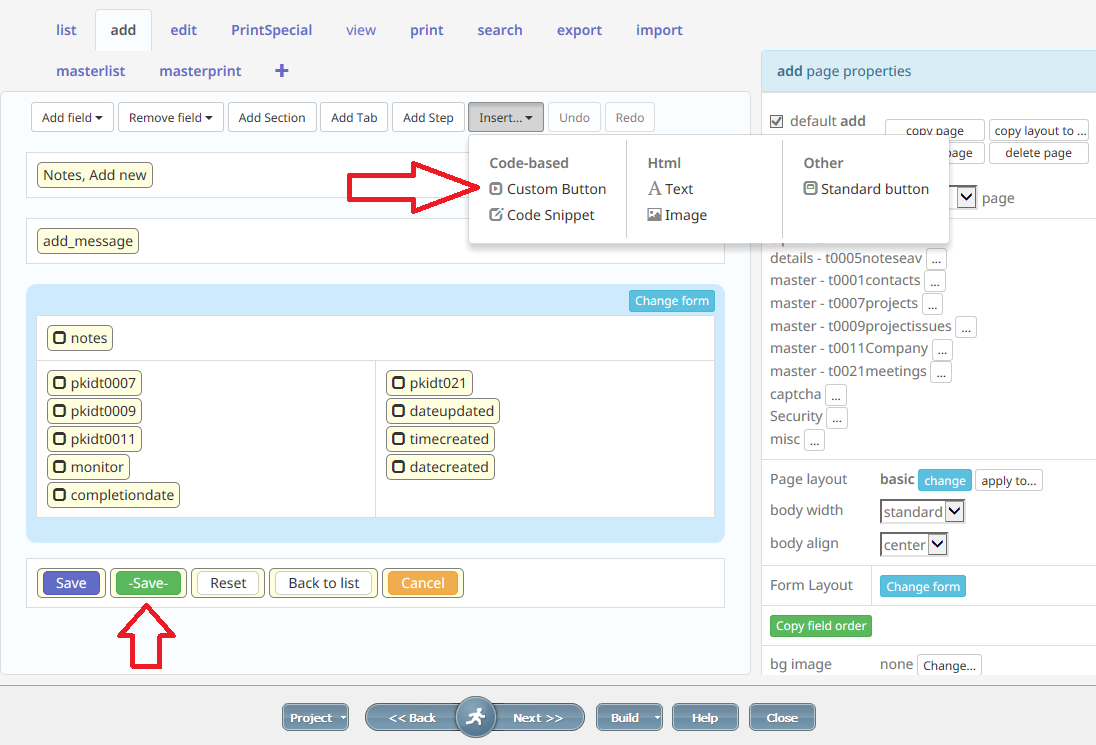
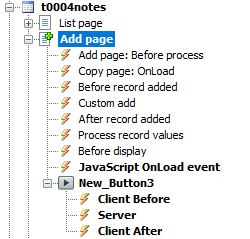
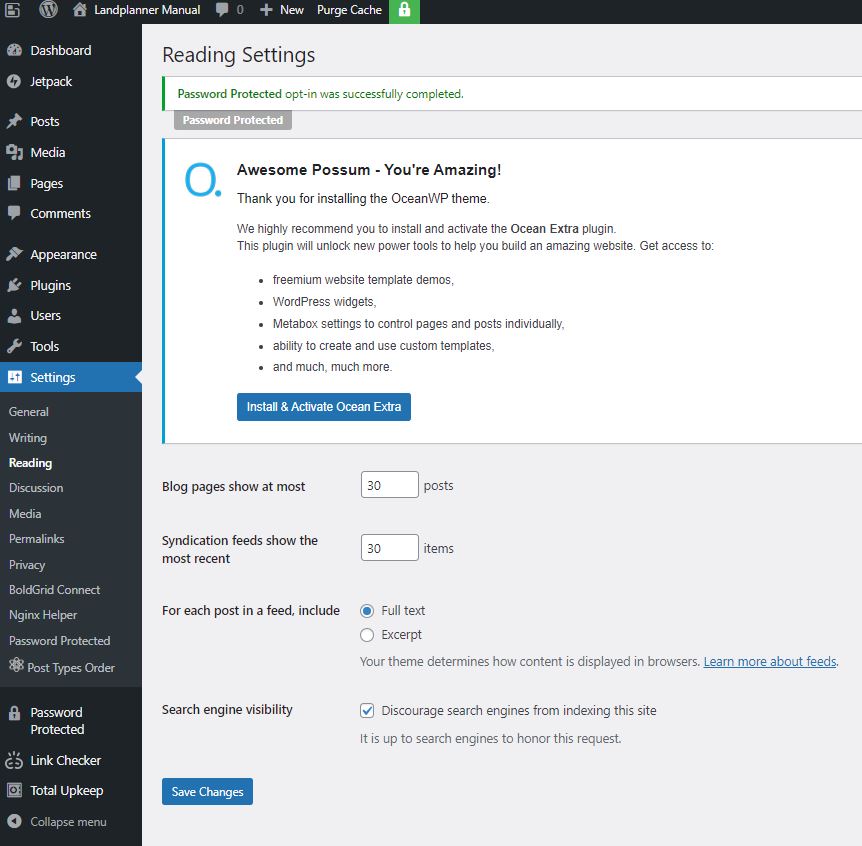
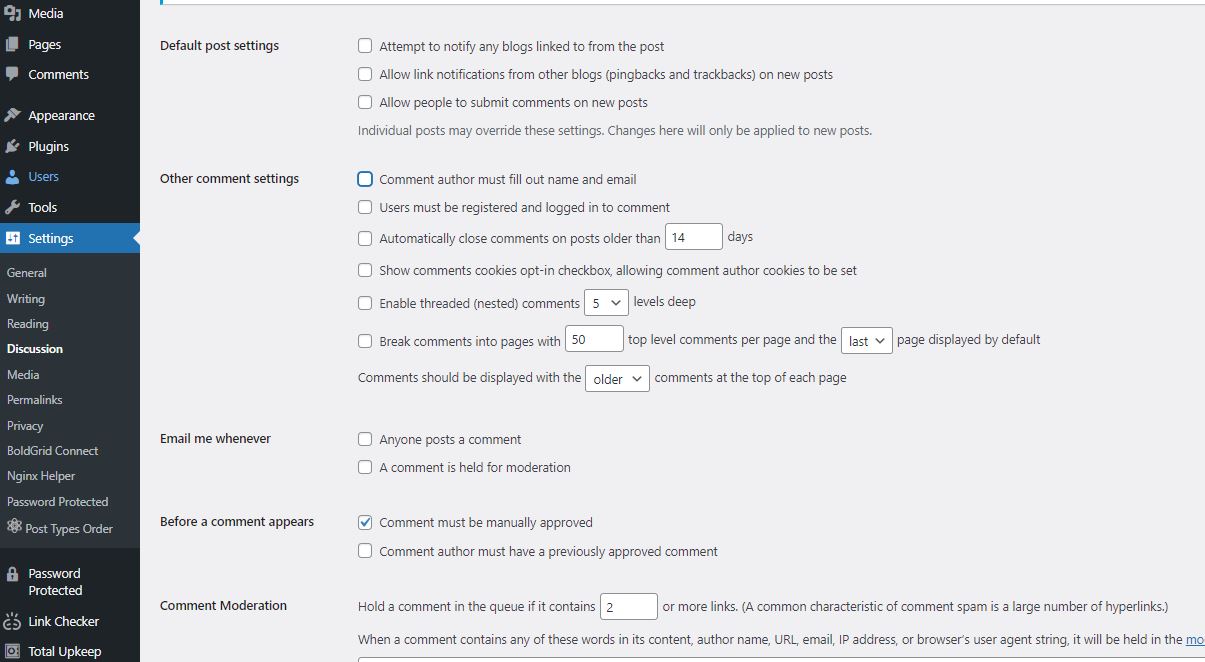
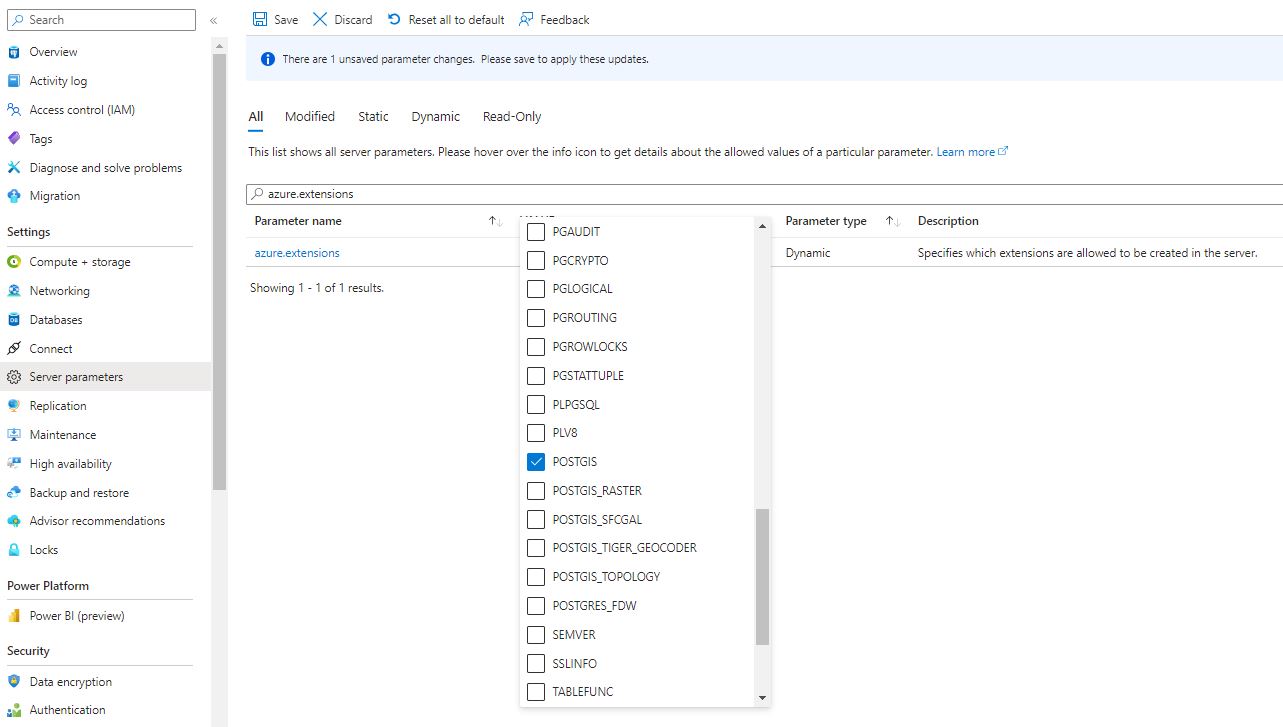
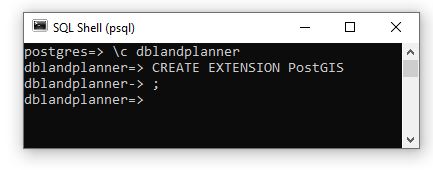
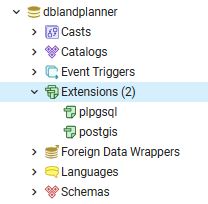
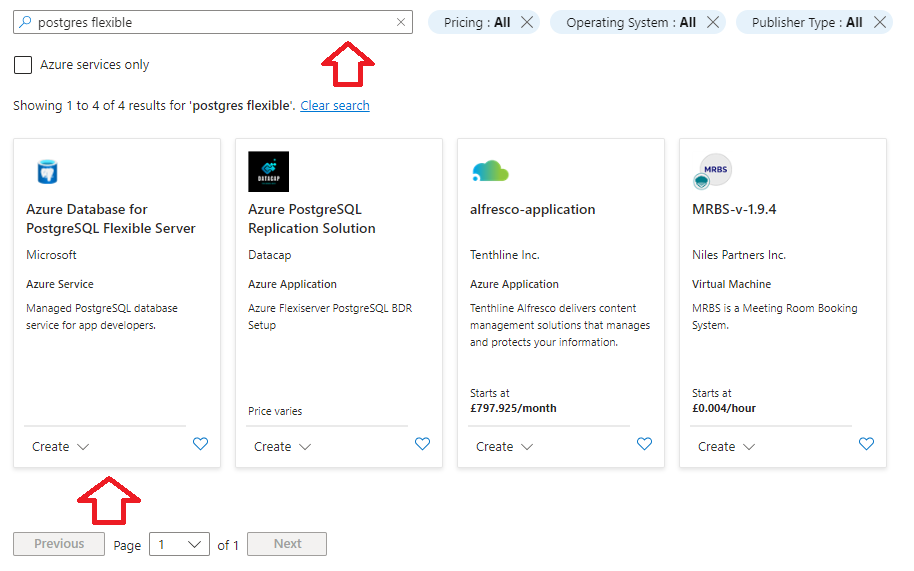
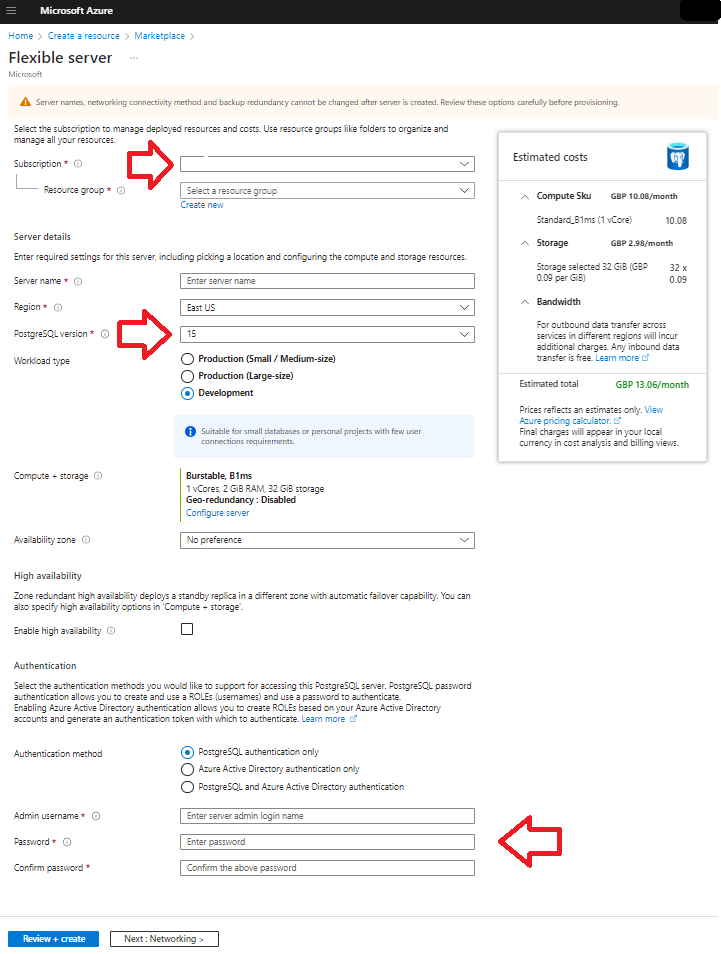
This is not tested at time of writing obtained from ChatGPT 4
Answer
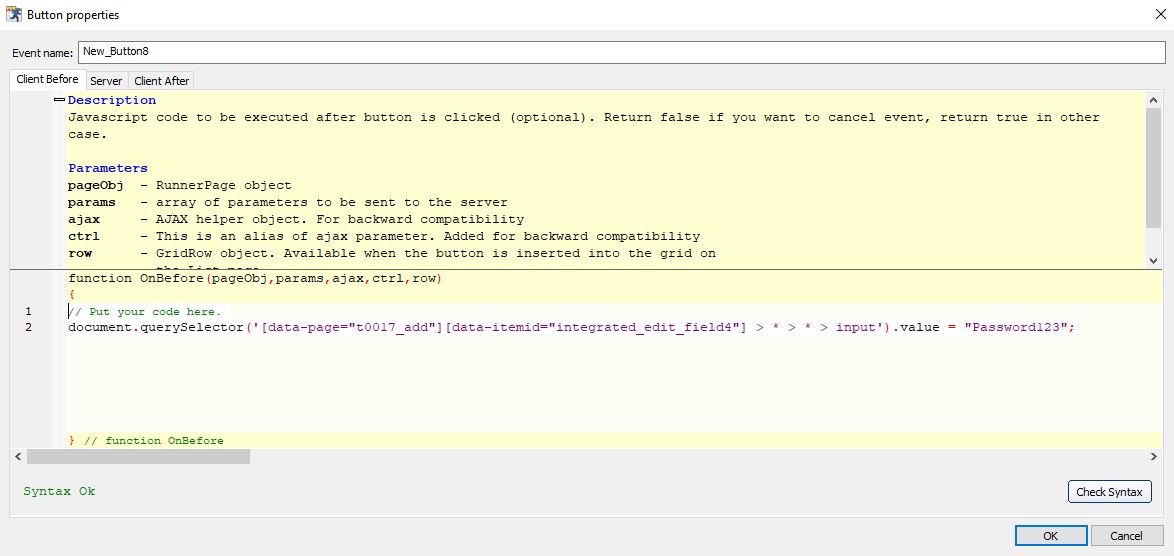
Sure, here’s an example of how you might implement the ConvertToUTC function to handle time zones like ‘London/Europe’. This example uses the AT TIME ZONE clause, which is available in SQL Server 2016 and later:
CREATE FUNCTION dbo.ConvertToUTC (@localDateTime DATETIME, @timeZone NVARCHAR(50))
RETURNS DATETIME
AS
BEGIN
-- Convert the local datetime to a datetimeoffset value using the specified time zone
DECLARE @datetimeoffset DATETIMEOFFSET = @localDateTime AT TIME ZONE @timeZone
-- Convert the datetimeoffset value to UTC
DECLARE @utcDateTime DATETIME = CONVERT(DATETIME, SWITCHOFFSET(@datetimeoffset, 0))
RETURN @utcDateTime
END
You can then use this function in a computed column definition:
ALTER TABLE YourTable
ADD UtcDateTime AS dbo.ConvertToUTC(field01, field02)
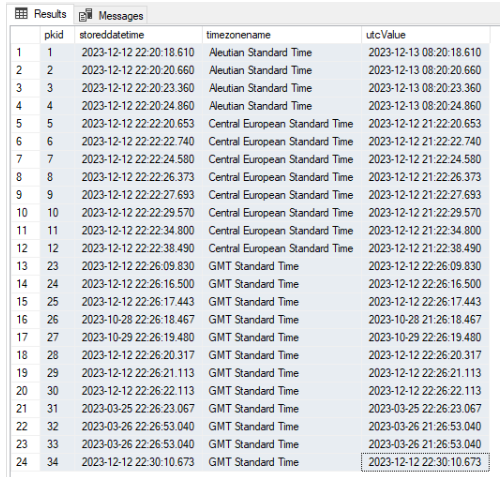
In this example, field02 should contain time zone names that are valid for the AT TIME ZONE clause. For example, ‘UTC’, ‘Pacific Standard Time’, ‘Central European Standard Time’, etc. For London, you would use ‘GMT Standard Time’.
Please note that this is just a basic example. The actual implementation would depend on how you’re storing time zone information and the specific requirements of your application. It’s also worth noting that handling date and time conversions can be complex due to factors like daylight saving time, so it’s important to thoroughly test your solution to ensure it handles all edge cases correctly.
If you’re frequently performing these types of conversions, you might want to consider storing datetime values in UTC directly in your database. This can simplify your data model and avoid potential issues with time zone conversions.
Question
Does AT TIME ZONE have a default value that will alter depending on whether the UK is under British Summer time?
Answer
Yes, the AT TIME ZONE clause in SQL Server does take daylight saving time into account. When you use a time zone name with this clause, it will automatically adjust the time based on the current daylight saving time rules for that time zone.
For example, if you use ‘GMT Standard Time’ (which is the time zone name for UK time in SQL Server), it will automatically show the correct offset for daylight saving when it is in effect.
Here’s an example:
SELECT GETDATE() AT TIME ZONE 'GMT Standard Time'
This will return the current date and time on the database BUT in my testing does NOT adjust the time to the timezone but will show the correct time zone OFFSET for the date for corrected for daylight saving i.e Greenwich Mean Time (GMT) or British Summer Time (BST), depending on the date.
Please note that the actual time zone names and their daylight saving time rules are based on the time zone data on the server where SQL Server is running. This data is updated through the Windows operating system, so it’s important to keep your servers up-to-date to ensure that the time zone rules are accurate.
And here are what I think are the supported time zones
MS Azure supported time zone values
Post-script
A lot of online editors won’t let you run the At Time Zone function but this one does..
dofactory
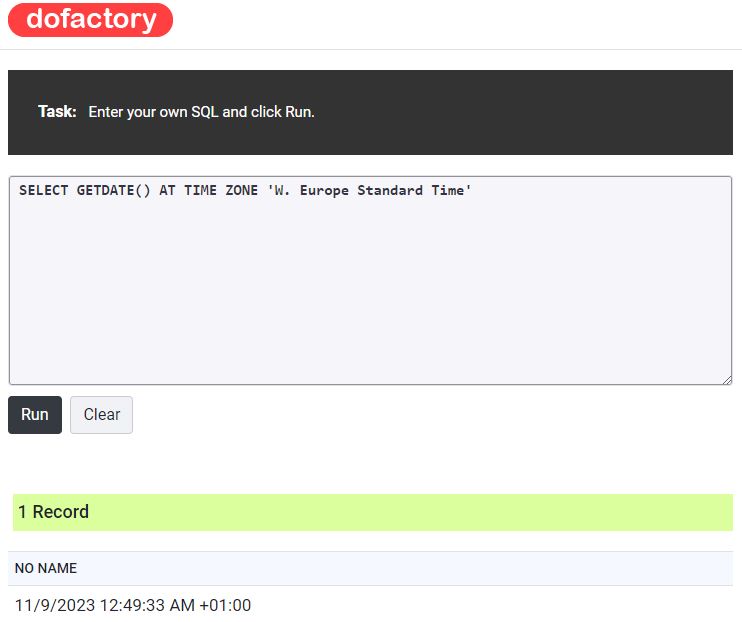
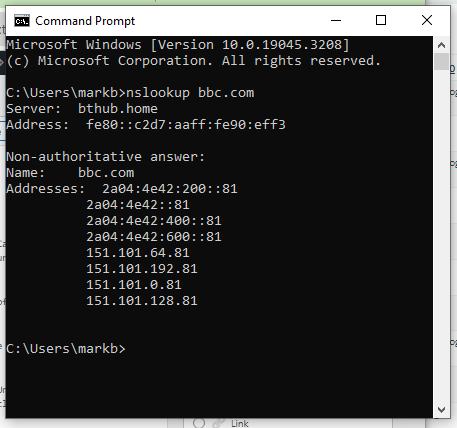
Comparing the time to my location and the time where I am I can tell that this is Pacific Standard Time – i.e Western America – California perhaps.
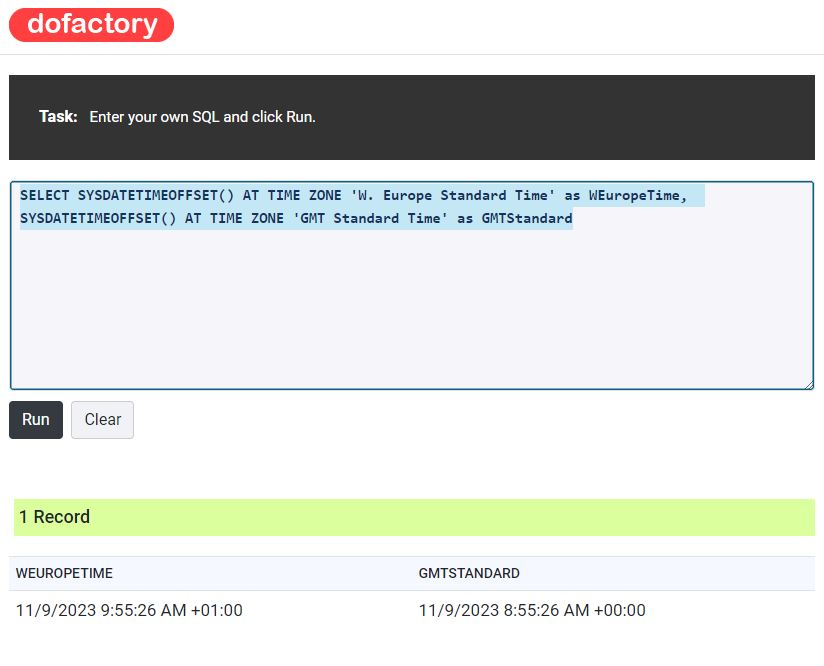
We also note that the time isn’t adjusted to the stated timezone but we do see the offset (see +01:00 in record return) Again this is because per se it doesn’t tell you what the server is set to but by using the sysdatetimeoffset we can correct the server time back to UTC and the adjust for timezone see second code example. The Timezone although included in the time is again be stated.
SELECT SYSDATETIMEOFFSET() AT TIME ZONE 'W. Europe Standard Time' as WEuropeTime,
SYSDATETIMEOFFSET() AT TIME ZONE 'GMT Standard Time' as GMTStandard
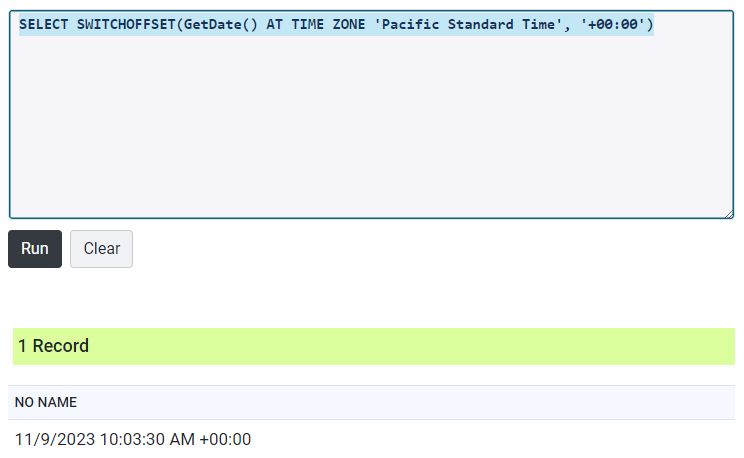
And so there is a direction to timezone switch – In the above we have mainly been switching from UTC to a timezone but the below switches from a timezone to UTC which is what we will need if we are storing the input as a datetime and a separate timezone for each record.
SELECT SWITCHOFFSET(GetDate() AT TIME ZONE 'Pacific Standard Time', '+00:00')
Remember though timezones are held outside SQL Server databases on the server and as such are non deterministic. This is a good demonstration of determinism in practice
Deterministic algorithms are entirely predictable and always produce the same output for the same input.
Non-deterministic algorithms may produce different outputs for the same input due to random events or other factors.