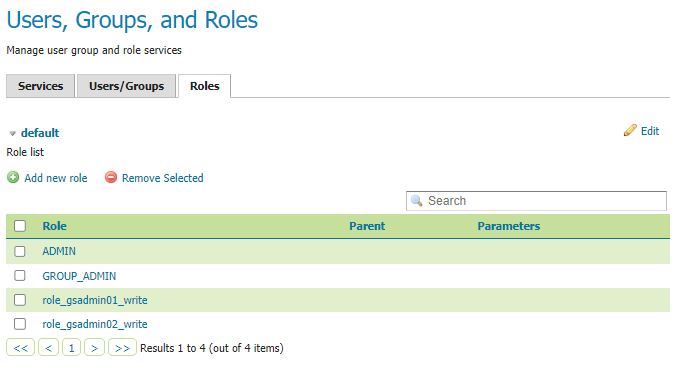
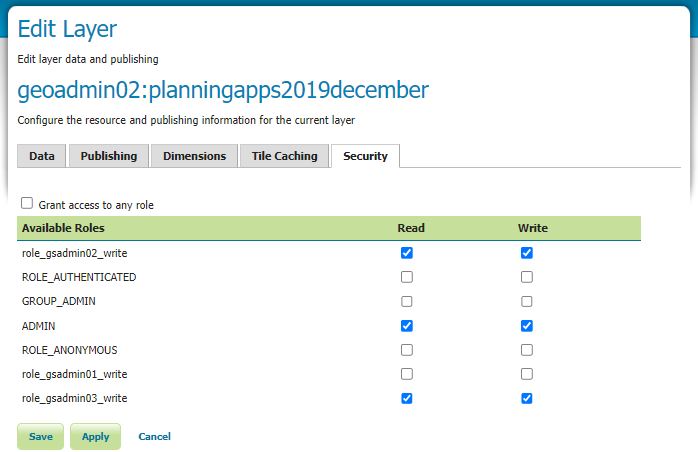
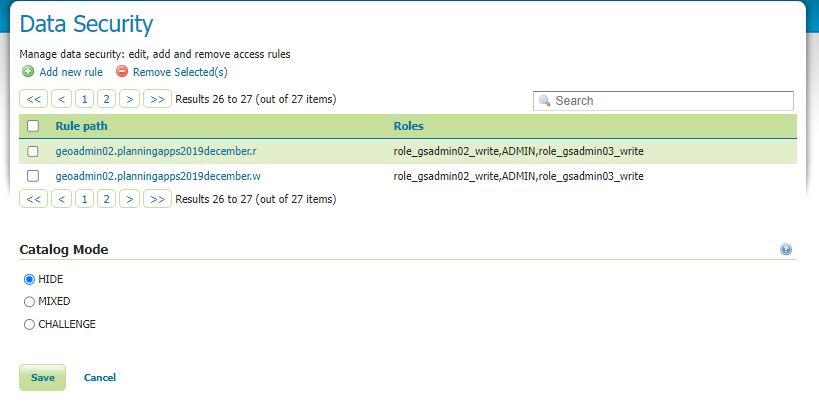
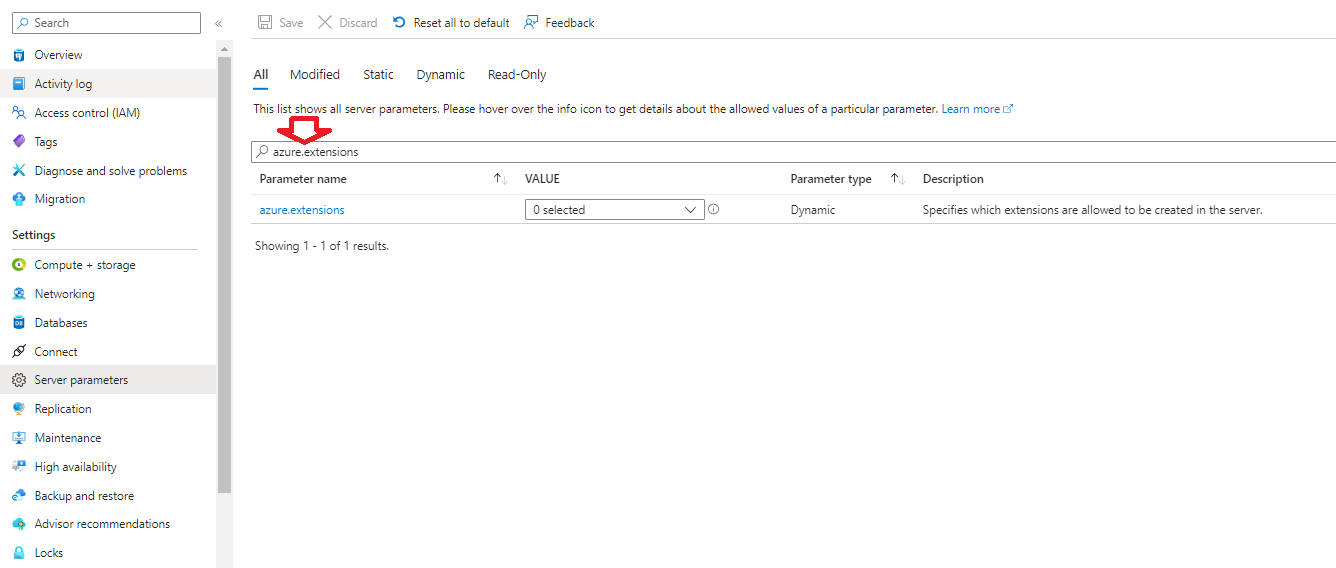
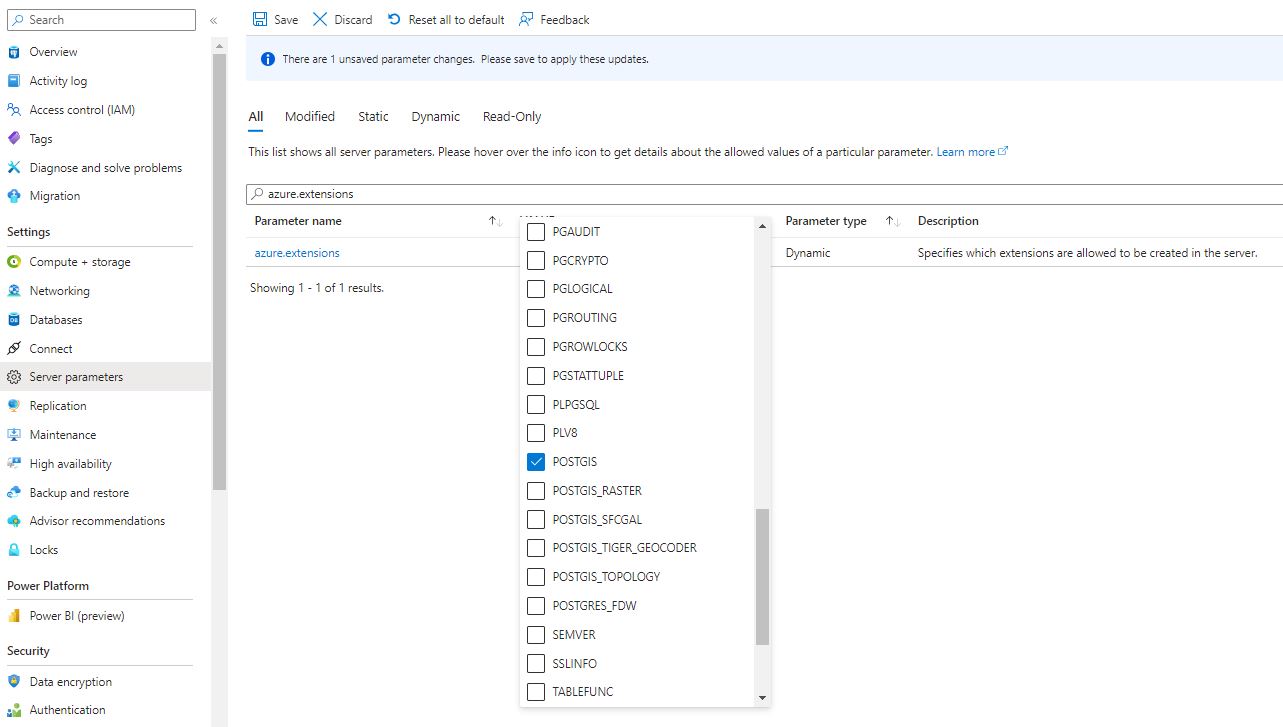
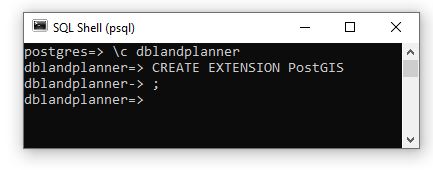
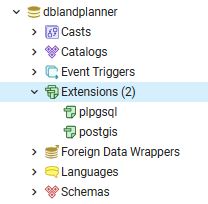
This is a subject I continually come back to and here I lay out my ideas on the two I believe leading patterns for use.
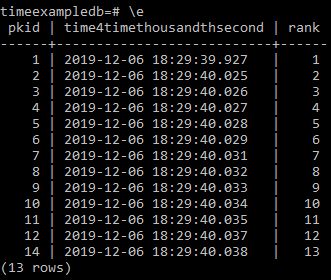
In dimensional modelling, slowly changing dimensions (SCDs) deal with the problem of change over time. How do we record that an entity — say, a customer, a land parcel, or a planning application — has changed some of its descriptive attributes, without losing the historical picture?
Most practitioners are familiar with the classic SCD Types (1–6), but the implementation details are where things get interesting, especially when your database design uses child tables to record change events rather than updating a single record in place.
1. The Child-Table Pattern
In this design, each entity has a parent table — say t001application — that holds the stable identifier (the surrogate key), and a child history table — say t002applicationhistory — that stores the time-stamped changes.
CREATE TABLE t001application (
gid serial PRIMARY KEY,
app_ref text NOT NULL
);
CREATE TABLE t002applicationhistory (
gid serial PRIMARY KEY,
pkidt001 integer REFERENCES t001application(gid),
status text,
valid_from date NOT NULL,
valid_to date
);
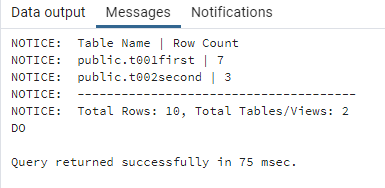
Each time the status or metadata changes, a new row is inserted into the child table.
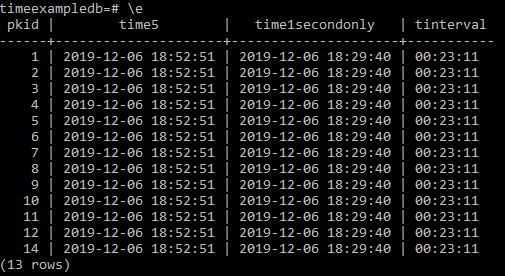
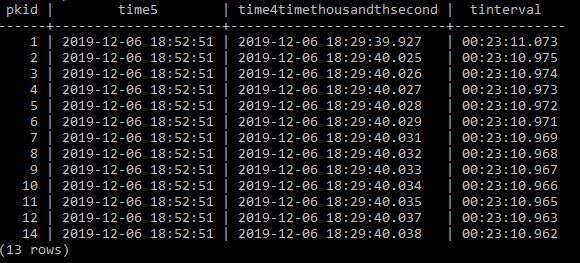
This approach works beautifully for auditing and temporal queries — you can reconstruct the full timeline of changes, or select the record valid on a specific date.
2. The “Current Value” Problem
The question is: how do we expose the current value of an attribute (e.g. the current application status) to applications or dashboards?
There are two common strategies:
Trigger-based update
A database trigger fires on insert or update in the history table, recalculating and updating the current value in the parent table.
Dynamic query or view
A query or materialised view calculates the current value at runtime, for example:
SQL
SELECT p.gid, h.status
FROM t001application p
JOIN t002applicationhistory h
ON p.gid = h.pkidt001
WHERE h.valid_to IS NULL;
or more flexibly
SELECT p.gid, h.status
FROM t001application p
JOIN LATERAL (
SELECT status
FROM t002applicationhistory h2
WHERE h2.pkidt001 = p.gid
ORDER BY valid_from DESC
LIMIT 1
) h ON TRUE;
3. Triggers: The “Static Snapshot” Approach
A trigger offers immediate performance benefits. The parent table always contains the most recent status — no need to compute it dynamically.
However, the trade-off is temporal rigidity.
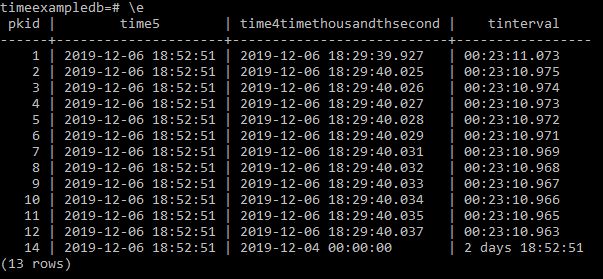
Because the trigger fires only on change, the “current” value is frozen until the next update occurs. If a future-dated record already exists in the child table, the trigger will not recalculate until that record becomes effective — unless the trigger logic explicitly handles future dates (which adds complexity).
Triggers also bake logic into the database layer, making it harder to adjust interpretation rules later. They are excellent for OLTP systems where performance and immediate consistency matter more than temporal flexibility.
4. Dynamic Queries: The “Time-Aware” Approach
Dynamic queries, or views that compute the latest state on demand, shift the calculation to query time rather than update time.
This means the query can flexibly interpret future or past effective dates:
You can write one version to show “as of today”.
Another version for “as of 1 January 2025”.
Or a version that forecasts “as of next month”, using the same data.
The downside, of course, is runtime cost — especially with large child tables. Every query has to calculate the current (or relevant) state. Indexing on pkidt001 and valid_from becomes essential, and caching via materialised views may be worthwhile.
But this approach aligns better with analytical systems and reporting environments — where temporal accuracy and future-aware insights are more valuable than transactional speed.
5. Why a Query Can Be “Better for the Future”
This subtle difference — when you calculate — shapes the database’s ability to reflect time correctly.
Because the dynamic query evaluates at the moment of viewing, it can take account of changes with valid_from dates in the future. In effect, it understands “planned” states that triggers ignore until the actual update event occurs.
6. Choosing Between Them
You might summarise the design choice like this:
Use triggers when:
Use dynamic queries when:
7. Conclusion
In slow changing dimensions — especially in a child-table temporal design — the real question isn’t how fast the dimension changes, but when you choose to acknowledge the change.
A trigger updates the moment the data changes.
A dynamic query updates the moment you look at it.
For systems that need to reflect not only what has changed but what will change, the dynamic query approach offers a quiet but powerful advantage: it lets your database stay in sync not just with the past, but with the future too.