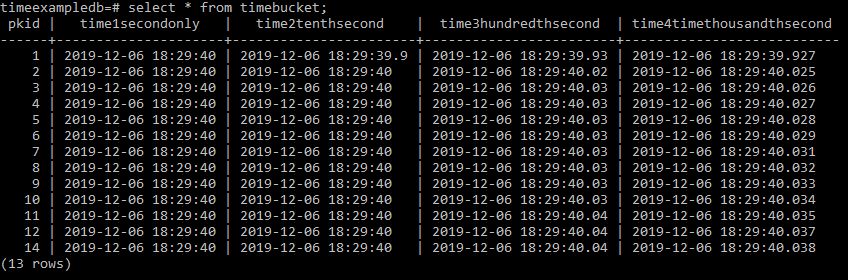
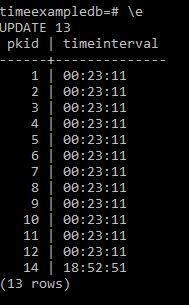
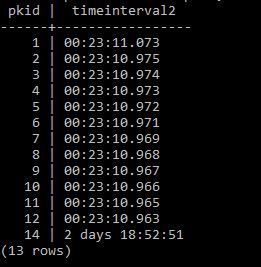
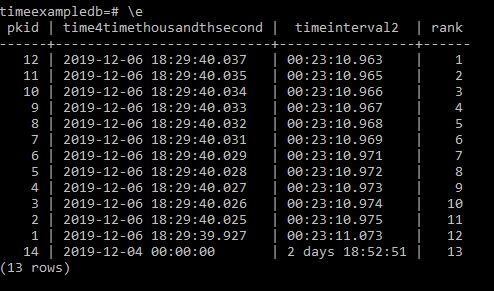
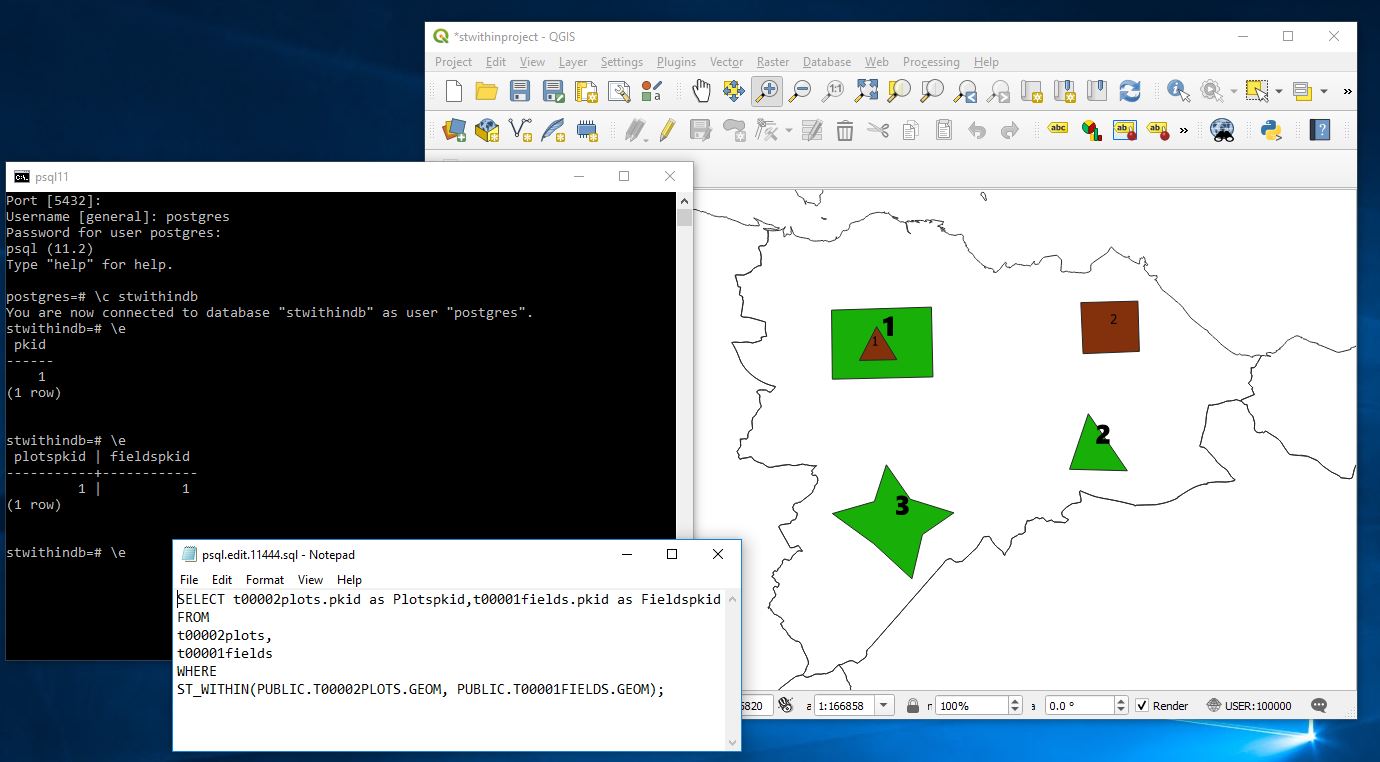
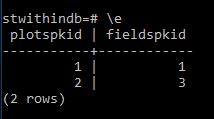
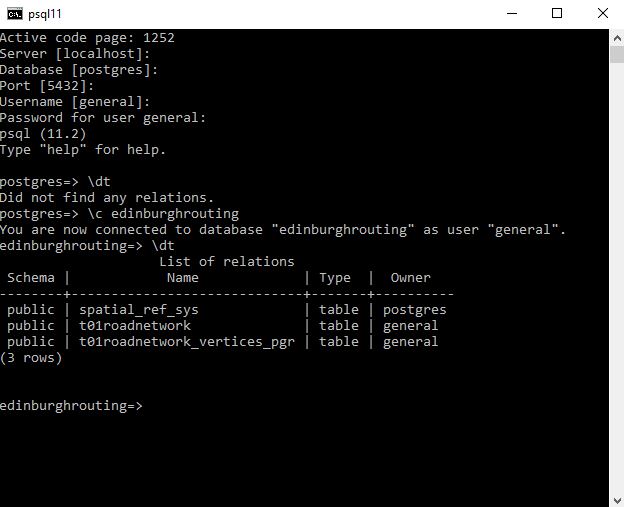
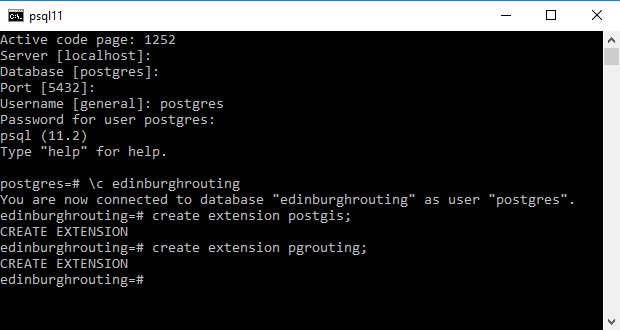
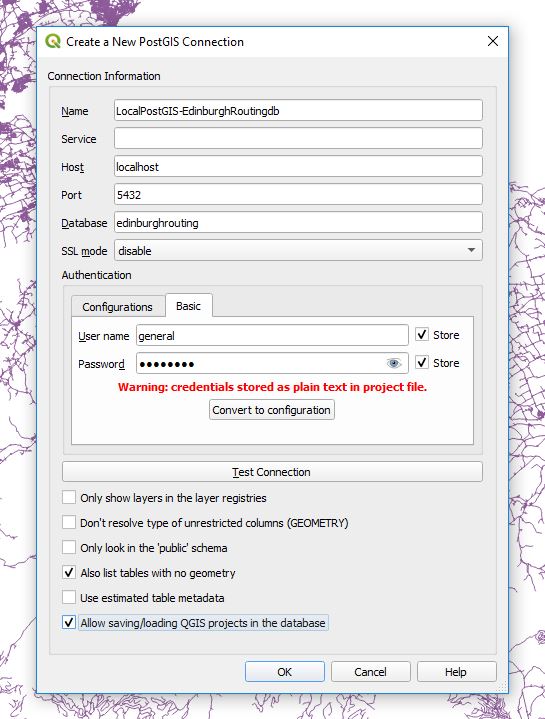
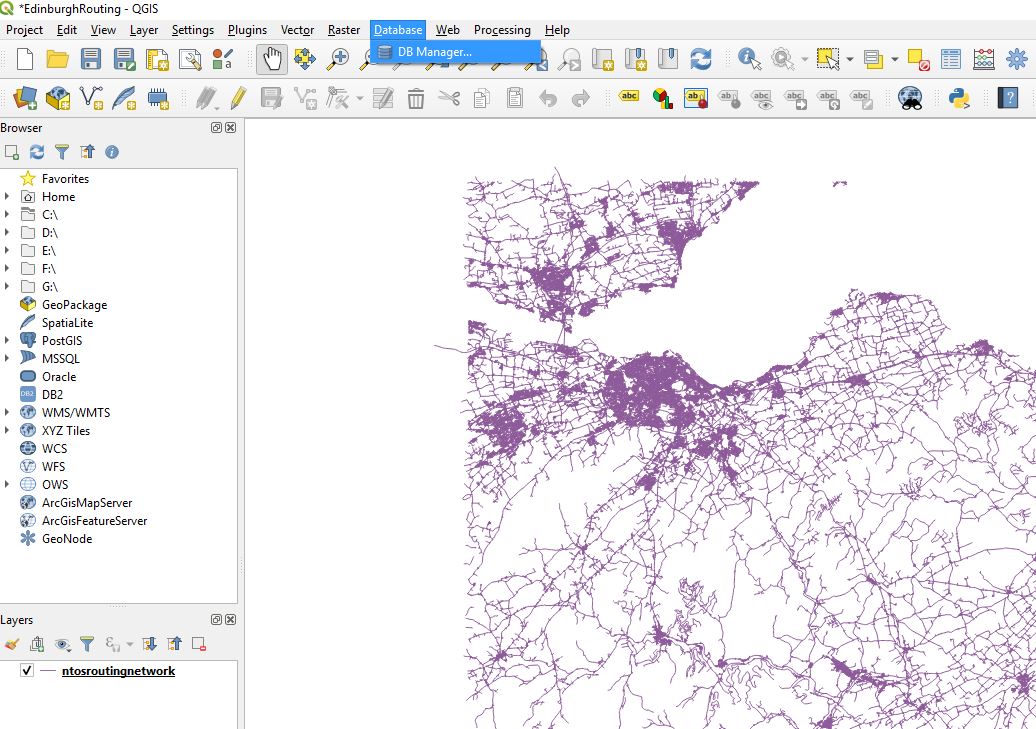
In Postgres and a number of other databases you cannot directly set a columns’ default value to come from another table. Here I talk through how you can setup another table and use a trigger to pull the value from that table and insert it as a default value into a field of your choice if on Insert the value is null.
Postgres
-- Parent table
CREATE TABLE t002defaultvalues (
gid bigint GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
warehouse text
);
-- Stock table
CREATE TABLE t001stock (
gid bigint GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
warehouse text
);
-- Function to fetch default warehouse
CREATE OR REPLACE FUNCTION set_default_warehouse()
RETURNS trigger AS $$
BEGIN
IF NEW.warehouse IS NULL THEN
SELECT warehouse
INTO NEW.warehouse
FROM t002defaultvalues
WHERE gid = 1; -- adjust if you want another rule
END IF;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
-- Trigger to apply the function
CREATE TRIGGER trg_t001stock_default_warehouse
BEFORE INSERT ON t001stock
FOR EACH ROW
EXECUTE FUNCTION set_default_warehouse();
SQL Server (T-SQL)
In SQL Server, defaults can’t reference other tables, so an AFTER INSERT trigger updates only the newly inserted rows (via the inserted pseudo-table).
-- Parent table
CREATE TABLE dbo.t002defaultvalues (
gid BIGINT IDENTITY(1,1) PRIMARY KEY,
warehouse NVARCHAR(MAX) -- TEXT is deprecated in SQL Server
);
-- Stock table
CREATE TABLE dbo.t001stock (
gid BIGINT IDENTITY(1,1) PRIMARY KEY,
warehouse NVARCHAR(MAX) NULL
);
GO
-- Trigger: fill warehouse from t002defaultvalues when NULL
CREATE TRIGGER dbo.trg_t001stock_default_warehouse
ON dbo.t001stock
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
UPDATE s
SET s.warehouse = dv.warehouse
FROM dbo.t001stock AS s
INNER JOIN inserted AS i
ON s.gid = i.gid
CROSS APPLY (
SELECT TOP (1) warehouse
FROM dbo.t002defaultvalues
WHERE gid = 1 -- adjust rule if needed
) AS dv
WHERE s.warehouse IS NULL;
END;
GO
-- Example
INSERT INTO dbo.t002defaultvalues (warehouse) VALUES (N'Main Depot');
INSERT INTO dbo.t001stock (warehouse) VALUES (NULL); -- will be set by trigger
MariaDB
In MariaDB, a BEFORE INSERT trigger can assign NEW.warehouse from a scalar subquery.
-- Parent table
CREATE TABLE t002defaultvalues (
gid BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,
warehouse TEXT
);
-- Stock table
CREATE TABLE t001stock (
gid BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,
warehouse TEXT NULL
);
DELIMITER $$
-- Trigger: fill warehouse from t002defaultvalues when NULL
CREATE TRIGGER trg_t001stock_default_warehouse
BEFORE INSERT ON t001stock
FOR EACH ROW
BEGIN
IF NEW.warehouse IS NULL THEN
SET NEW.warehouse = (
SELECT warehouse
FROM t002defaultvalues
WHERE gid = 1 -- adjust rule if needed
LIMIT 1
);
END IF;
END$$
DELIMITER ;
-- Example
INSERT INTO t002defaultvalues (warehouse) VALUES ('Main Depot');
INSERT INTO t001stock () VALUES (); -- will be set by trigger
Adjust WHERE gid = 1 to whatever selection rule you need (e.g., ORDER BY created_at DESC LIMIT 1, or WHERE active = 1 LIMIT 1).